Cuales recursos?
Thunderbird no solo recibe emails. Aparte de otros clientes de email muy aceptados como Outlook o iMail, Thunderbird tiene una infinidad de recursos limitados solamente por nuestros propios conocimientos, ya que por ser OpenSource, podemos hasta "reescribir" el código para adaptarlo a nuestras necesidades.
Esto de reescribir el código es por supuesto una exageracion una porque pocos estamos en la capacidad de hacerlo y dos porque no es necesario porque los recursos que ya tiene son muy grandes y poderosos.
- Carpetas de Busqueda
- Carpetas (IMAP)
- Marcas con estrella (kennzeichnung)
- Palabras clave (schlagworte)
- Filtros rápidos
- Filtros
- Convertir en
-- Cita
-- Nota
- Columnas y Configuracion de Columnas para Carpetas
Ejemplo:
Casi una vez al mes pero irregularmente me llega un email invitandome a una conferencia a la que quiero participar.
Tengo varias reglas para que todos los email del departamento invitador se metan en una carpeta de notificaciones, pero quisiera que exactamente esas invitaciones no se me pasen desapercibidas.
En mi compañia los departamentos escriben nombrandose con corchetes en el asunto. El asunto es un poco variable, aunque he observado que una palabra siempre esta alli. Por esto, genero un filtro que busque dentro de la carpeta DEPTO-CONT la cadena "invitacion" y marque esta con mi palabra clave "citas" y agrege una estrella.
Como en la carpeta hay tambien invitaciones anteriores, entonces pierdo nuevamente un poco el objetivo, con lo que complemento el filtro con "antiguedad en días" y asi le pido que solo marque asi los emails que tienen menos de 60 dias.
Una posibilidad es tambien copiar o mover los emails que cumplen la regla a otra carpeta, llamada por ejemplo "Citas-Actuales". Copiar tiene una desventaja: cada vez que aplicas el filtro a la carpeta copia nuevamente lo mismo. Mover tiene la desventaja de que cuando busques los emails del departamento, los de estas citas no van a estar en esta carpeta. Para que esta repeticion no suceda, puedes agregar el filtro "estatus""no es""marcado", pues como la marca la agrega el filtro al copiar, no volvera a aplicarse el filtro en los emails ya copiados porque al mismo tiempo fueron marcados.
Esta desventaja de mover tambien se puede solventar con una carpeta de busqueda, pues es virtual y puede contener emails que estan en diferentes carpetas.
Ademas de estos recursos estandar de Thunderbird, puedo recomendar los Addons
ColorFolder
RegExSuche
ThemeFontSizeChanger
CalendarTweks
viernes, 14 de julio de 2017
martes, 13 de junio de 2017
Como usar una carpeta compartida en la red para guardar Backups de Time Machine de Apple Mac
Para la mayoría, Apple Mac resulta un icono de la facilidad y amabilidad con el usuario. Claro que el usuario solo abre la maquinilla y lo ve todo bonito, pero cuando se trata de administrar Mac en un ambiente empresarial es otra la historia.
Los usuarios Windows, cuentan con Shadows Copy. Si los usuarios Mac guardan en una Carpeta de servidor windows esta funcion estar corriendo "por debajo de la mesa". Si un archivo se pierde o borra, se podrá recuperar del servidor windows, pero solamente con un Cliente windows en el que se haga clic con el boton derecho y luego en Versiones.
Este clic no estará presente en Mac, aunque las versiones estén ahí.
Claro que hay mucho que se puede hacer: Maquinas Virtuales, Servidores de Remote Desktops Services, Exploradores de Archivos especializados, etc. Lamentablemente todo resulta "pañitos calientes" o en IT-Jerga "Worksarounds".
Por otro lado, utilizar una Carpeta de Servidor Windows con SMB no siempre resulta tan facil con mac. Mac no tiene GPOs con las que podamos mandar los perfiles completos al servidor y una sincronizacion no es de mi agrado (pocas veces sabe el usuario que esta sincronizado y que no).
Pero Mac tiene su propia solución, y además que se ve bonita (esto es siempre importante para Mac y sus usuarios) se llama Time Machine o Maquina del Tiempo. En TM puedes ver como en el tiempo tus documentos y toda tu máquina ha pasado por el tiempo y puedes restablecer con una increible facilidad las versiones pasadas.
Claro, tienes que enchufar un disquito externo a tu mac... o también correrá bien (o mejor) si te compras una no tan económica Cápsula del Tiempo, con la que podrás guardar tus Backups por el aire.
Pero si la empresa tiene un grande y poderoso servidor SMB, porque necesitamos unos aparatitos de jugete como las capsulas del tiempo?. Eso se puede preguntar cualquier IT administrador que tenga mas de dos dedos de frente y algunos usuarios con fundamento.
Pues porque no es tan fácil. Lo ideal sería que mac nos permitiera en Time Machine, encontrar las Shares que estan disponibles en la red y que podamos decirle "aqui por favor". Pero esto no es posible. Si bien existe un "hack" bastante elegante y eficiente que nos lo permitirá:
Crea una Imagen de Disco con la aplicación estandard de administracion de Discos. Debe ser HFS-J (journaled) y de crecimiento automatico "parseled bunded" ni mas esta decir que del tamaño adecuado para tus documentos.
Pon esta imagen en tu carpeta de red (Share) y luego montala en el sistema de archivos (simple doble clic)
Ahora manda a Time Machine a usar esta unidad montada con
Pero esto es tema de otro Blog donde me ocupo de esto.
Los usuarios Windows, cuentan con Shadows Copy. Si los usuarios Mac guardan en una Carpeta de servidor windows esta funcion estar corriendo "por debajo de la mesa". Si un archivo se pierde o borra, se podrá recuperar del servidor windows, pero solamente con un Cliente windows en el que se haga clic con el boton derecho y luego en Versiones.
Este clic no estará presente en Mac, aunque las versiones estén ahí.
Claro que hay mucho que se puede hacer: Maquinas Virtuales, Servidores de Remote Desktops Services, Exploradores de Archivos especializados, etc. Lamentablemente todo resulta "pañitos calientes" o en IT-Jerga "Worksarounds".
Por otro lado, utilizar una Carpeta de Servidor Windows con SMB no siempre resulta tan facil con mac. Mac no tiene GPOs con las que podamos mandar los perfiles completos al servidor y una sincronizacion no es de mi agrado (pocas veces sabe el usuario que esta sincronizado y que no).
Pero Mac tiene su propia solución, y además que se ve bonita (esto es siempre importante para Mac y sus usuarios) se llama Time Machine o Maquina del Tiempo. En TM puedes ver como en el tiempo tus documentos y toda tu máquina ha pasado por el tiempo y puedes restablecer con una increible facilidad las versiones pasadas.
Claro, tienes que enchufar un disquito externo a tu mac... o también correrá bien (o mejor) si te compras una no tan económica Cápsula del Tiempo, con la que podrás guardar tus Backups por el aire.
Pero si la empresa tiene un grande y poderoso servidor SMB, porque necesitamos unos aparatitos de jugete como las capsulas del tiempo?. Eso se puede preguntar cualquier IT administrador que tenga mas de dos dedos de frente y algunos usuarios con fundamento.
Pues porque no es tan fácil. Lo ideal sería que mac nos permitiera en Time Machine, encontrar las Shares que estan disponibles en la red y que podamos decirle "aqui por favor". Pero esto no es posible. Si bien existe un "hack" bastante elegante y eficiente que nos lo permitirá:
Crea una Imagen de Disco con la aplicación estandard de administracion de Discos. Debe ser HFS-J (journaled) y de crecimiento automatico "parseled bunded" ni mas esta decir que del tamaño adecuado para tus documentos.
Pon esta imagen en tu carpeta de red (Share) y luego montala en el sistema de archivos (simple doble clic)
Ahora manda a Time Machine a usar esta unidad montada con
sudo tmutil setdestination /Volumes/TimeMachineDespues tendrás el problema de montar esta Carpeta de Servidor o Share automaticamente en mac, pues aunque esto parezca evidente, y de echo en un clic en Windows, resulta un dolor de cabeza en mac. Sobre todo, si tus usuarios no son Administradores de su Cliente. Pero esto es tema de otro Blog donde me ocupo de esto.
miércoles, 10 de mayo de 2017
Thunderbird deja todos los documentos anexos en en escritorio de Mac
escribo "de Mac" porque realmente no habi visto esto antes en Windows, quizas tambien pasa, quizas le pasa a alguien. Pero esta molesto hábito se puede configurar relativamente fácil y los encontramos en en link:
http://cote.cc/blog/stop-thunderbird-from-littering-your-desktop-with-attachments
Por si el link se pierde, o la pagina, o simplemente necesitas un manual es espanol, lo explico a continuacion:
- Ve a configuracion: Extras --> Configuracion --> Avanzada --> Trabajar la Configuracion (about:config)
- Ahi buscas la clave :
http://cote.cc/blog/stop-thunderbird-from-littering-your-desktop-with-attachments
Por si el link se pierde, o la pagina, o simplemente necesitas un manual es espanol, lo explico a continuacion:
- Ve a configuracion: Extras --> Configuracion --> Avanzada --> Trabajar la Configuracion (about:config)
- Ahi buscas la clave :
"browser.helperApps.deleteTempFileOnExit" sin comillas, que debe estar presente y configurada como "False".
- Dale doble clic y deberia cambiar a "True", sino haslo manualmente.
y ya esta, con esto Thunderbird borrara todos los archivos temporales dejados al terminar la sesion.
jueves, 4 de mayo de 2017
Identacion para archivos XML sin identacion en TextWrangler
TextWrangler es excelente. Si algo le puede criticar es que es un poquito lento, pero para lo brinda en comparacion con los rapidos, se puede soportar.
Un problemita que me ocupó mientras trataba de editar archivos de configuracion sin saltos de linea en xml, es justamente que no tienen saltos de linea, es decir que toda la configuración era una sola linea. A pesar de que esto pueda parecer lógico, tambien debe resultar logico que se pueda crear una identacion, ya que cada linia posee un nuevo tag con la forma <> y esto lo puede encontrar un programa.
Entonces por esto me di a la busqueda de una solucion para ello y encontre esta bella solucion:
https://magp.ie/2010/02/15/format-xml-with-textwrangler/
No por copiar, sino porque me desagrada que a veces cuando guardo unos vinculos con buena informacion desaparecen de internet, pongo aqui tambien el contenido de la solución, sin dejar de agredecer a su autor original Eoin Gallagher
-----------------------------------------------------------------------------------------------------------------------
Simple guide
We want to add a UNIX script to TextWrangler so it can format an XML file… to do this, do this…
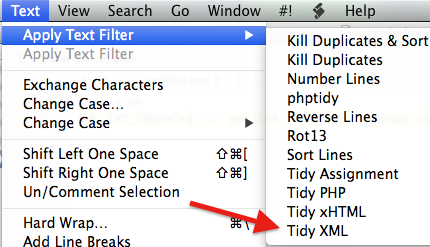
This is an interesting facility to extend an already great text editor, and I will be looking into more cool scripts that can hopefully lessen my daily annoyances.
UPDATED:: Added UTF8 encoding, thanks Rolan.
UPDATED:: Added a post to format PHP code in TextWrangler.
UPDATED:: Updated for TextWrangler version 4.5.8.
---------------------------------------------------------------------------------------------------------------------
Un problemita que me ocupó mientras trataba de editar archivos de configuracion sin saltos de linea en xml, es justamente que no tienen saltos de linea, es decir que toda la configuración era una sola linea. A pesar de que esto pueda parecer lógico, tambien debe resultar logico que se pueda crear una identacion, ya que cada linia posee un nuevo tag con la forma <> y esto lo puede encontrar un programa.
Entonces por esto me di a la busqueda de una solucion para ello y encontre esta bella solucion:
https://magp.ie/2010/02/15/format-xml-with-textwrangler/
No por copiar, sino porque me desagrada que a veces cuando guardo unos vinculos con buena informacion desaparecen de internet, pongo aqui tambien el contenido de la solución, sin dejar de agredecer a su autor original Eoin Gallagher
-----------------------------------------------------------------------------------------------------------------------
Simple guide
We want to add a UNIX script to TextWrangler so it can format an XML file… to do this, do this…
- Open TextWrangler and open a new text file.
- Copy and paste the code below into this file.
1
2
| #!/bin/shXMLLINT_INDENT=$'\t' xmllint --format --encode utf-8 - |
- Save the file, something like Tidy XML.sh, in the
~/Library/Application Support/TextWrangler/Text Filters/folder. - Now anytime you want to format an XML file, just go to the Text menu and select the Tidy XML.sh script and BOOM, neat tidy XML.
This is an interesting facility to extend an already great text editor, and I will be looking into more cool scripts that can hopefully lessen my daily annoyances.
UPDATED:: Added UTF8 encoding, thanks Rolan.
UPDATED:: Added a post to format PHP code in TextWrangler.
UPDATED:: Updated for TextWrangler version 4.5.8.
---------------------------------------------------------------------------------------------------------------------
miércoles, 12 de abril de 2017
Templates o Plantillas en Libre Office para Mac
Para crear Templates que se puedan usar en el futuro en LibreOffice, es necesario crear el template (mejor vacío) y luego guardarlo como template.
En las ayudas estandar de libre office aparece un camino facil de equivocar, puesto que (por lo visto en mac el camino es un poco distinto, hay discrepancias y redundancias)
Primero:
Crear un Documento con las características que deseamos. Luego guardarlo como plantilla con
File --> Templates --> Save as Template ---> MyTemplates --> Set as Default
Esto abrira un cuadro de Dialogo que permitira guardar la plantilla como estandar para los proximos documentos.
Si haz usado un documento existente, con contenido, siempre se abrira el contenido. Cosa que me parece tonta puesto que lo interesante es el formato.
De alguna manera se puede disculpar, puesto que es quizas pensado para que siempre aparezca el mismo titulo, asi como los pie de paginas y otras caracteristicas que son intermedias entre contenido y formato.
Si haz guardado la opcion "set as Default" cada nuevo documento contendrá automaticamente el contenido de esta plantilla incluyendo, contenido y formatos.
CUIDADO:
Si piensas que el Documento abierto lo puedes "save as" y luego escojer "template", hasta allí funcionará, pero luego no estará esta plantilla en "My Templates" ni mucho menos como estandar.
CUIDADO:
Cuida de guardar un Documento vacio con el contenido que deseas como estandar y no un texto en especial, pues aparecerá despues en cada nuevo documento
En las ayudas estandar de libre office aparece un camino facil de equivocar, puesto que (por lo visto en mac el camino es un poco distinto, hay discrepancias y redundancias)
Primero:
Crear un Documento con las características que deseamos. Luego guardarlo como plantilla con
File --> Templates --> Save as Template ---> MyTemplates --> Set as Default
Esto abrira un cuadro de Dialogo que permitira guardar la plantilla como estandar para los proximos documentos.
Si haz usado un documento existente, con contenido, siempre se abrira el contenido. Cosa que me parece tonta puesto que lo interesante es el formato.
De alguna manera se puede disculpar, puesto que es quizas pensado para que siempre aparezca el mismo titulo, asi como los pie de paginas y otras caracteristicas que son intermedias entre contenido y formato.
Si haz guardado la opcion "set as Default" cada nuevo documento contendrá automaticamente el contenido de esta plantilla incluyendo, contenido y formatos.
CUIDADO:
Si piensas que el Documento abierto lo puedes "save as" y luego escojer "template", hasta allí funcionará, pero luego no estará esta plantilla en "My Templates" ni mucho menos como estandar.
CUIDADO:
Cuida de guardar un Documento vacio con el contenido que deseas como estandar y no un texto en especial, pues aparecerá despues en cada nuevo documento
martes, 31 de enero de 2017
Trabajar con el Disco duro en Unix
Empezar con Linux puede ser duro, pero si una cosa esta complicada es el trabajo con discos. No me refiero por supuesto a la comoda interfaz grafica, donde hacemos clic y vemos propiedades, sino a trabajar al ciento por ciento con la consola, ya sea por gusto a las complicaciones o porque mantenemos algun(os) servidor(es) sin mejores posibilidades.
Bueno, para mi personalmente el tiempo del ahorro de recursos ya ha pasado. Mi primera computadora fue un 8088 con menos de un Mhz de Taktung mientras que las actuales tienen varios Procesadores con más de 3 GHz. Los servidores siempre estaban mejorcitos. Los programas tambien han mejorado su rendimiento, no todos crecen nada mas. Pero bueno, eso es al final cuestion de gustos y harina de otro costal.
Ver las Particiones de manera bastante explicativa:
df -h
hacer imagenes de disco
dd if=/dev/disco of=/home/desktop/tu_imagen.img --> puede ser que necesitas sudo!
este articulo me gusto:
https://wiki.archlinux.de/title/Image-Erstellung_mit_dd
Bueno, para mi personalmente el tiempo del ahorro de recursos ya ha pasado. Mi primera computadora fue un 8088 con menos de un Mhz de Taktung mientras que las actuales tienen varios Procesadores con más de 3 GHz. Los servidores siempre estaban mejorcitos. Los programas tambien han mejorado su rendimiento, no todos crecen nada mas. Pero bueno, eso es al final cuestion de gustos y harina de otro costal.
Ver las Particiones de manera bastante explicativa:
df -h
hacer imagenes de disco
dd if=/dev/disco of=/home/desktop/tu_imagen.img --> puede ser que necesitas sudo!
este articulo me gusto:
https://wiki.archlinux.de/title/Image-Erstellung_mit_dd
domingo, 8 de enero de 2017
Controlando el disco duro en linux, detener, dormir, reactivar
Estoy trabajando en desacerme de mis viejos moustrosos servidores y sustituirlos por mis viejas moustrosas portatiles. He empezado con crear un servidor KVM en una Lenovo Sl500. Por ahora todo va bien, pero a pesar de que el monitor esta en mínimo, y el portátil tiene control avanzado de Energía, el disco duro esta siempre trabajando y caliente.
Parece ser que por defecto el standby para discos en Linux viene desactivado, que se puede controlar con hdparm y que este control es solo por sesion y hay que hacerlo manual cada vez que se reinicia. En el siguiente blog encontre una solución que tengo que probar y con la que no estoy del todo satisfecho
http://www.tacticalcode.de/2013/01/festplatte-automatisch-in-standby-mit-hdparm-und-udev.html
Pero sigo buscando...
update 10:43
http://blog.is-a-geek.org/festplatten-in-den-standby-modus-versetzen-unter-ubuntu-desktopserver-mit-hd-idle
update 20.01.17
hoy he tenido un poco de tiempo para realizar pruebas. Primero, intenté configurar los discos a través de la herramienta webmin, que es mi favorita para facilitar el mantenimiento linux.
En webmin encontramos un apartado para esto y es;
hardware --> partition and local disks --> idle parameters --> Standby timeout
esto funciona en el momento, pero la configuracion no se guarda, todavia no he mirado porque,
Otra alternativa, hdparm es bastante aceptable, pero hay que configurarla a traves de scripts para que se funcion de manera automatica. Basicamente:
hdparm -C /dev/sda --> te dice el estado actual del sda
hdparm -y /dev/sda --> lo pone en descanso
hdparm -S 10 /dev/sda --> lo pone en descanso en un tiempo estimado
Parece ser que por defecto el standby para discos en Linux viene desactivado, que se puede controlar con hdparm y que este control es solo por sesion y hay que hacerlo manual cada vez que se reinicia. En el siguiente blog encontre una solución que tengo que probar y con la que no estoy del todo satisfecho
http://www.tacticalcode.de/2013/01/festplatte-automatisch-in-standby-mit-hdparm-und-udev.html
Pero sigo buscando...
update 10:43
http://blog.is-a-geek.org/festplatten-in-den-standby-modus-versetzen-unter-ubuntu-desktopserver-mit-hd-idle
update 20.01.17
hoy he tenido un poco de tiempo para realizar pruebas. Primero, intenté configurar los discos a través de la herramienta webmin, que es mi favorita para facilitar el mantenimiento linux.
En webmin encontramos un apartado para esto y es;
hardware --> partition and local disks --> idle parameters --> Standby timeout
esto funciona en el momento, pero la configuracion no se guarda, todavia no he mirado porque,
Otra alternativa, hdparm es bastante aceptable, pero hay que configurarla a traves de scripts para que se funcion de manera automatica. Basicamente:
hdparm -C /dev/sda --> te dice el estado actual del sda
hdparm -y /dev/sda --> lo pone en descanso
hdparm -S 10 /dev/sda --> lo pone en descanso en un tiempo estimado
viernes, 6 de enero de 2017
conectarse con un server por ssh usando una llave ida/rsa
ACTUALIZACION 21:11:2018
Si hemos perdido la clave publica, pero conservamos la privada. Podemos "recrearla" con el comando:
ACTUALIZACION 14:11:2018
Cuando creamos el par de claves, ssh-keygen nos va a mostrar una salida artistica de la llave que se llama randomart.
Este dibujito, no lo volveremos a ver nunca mas si no lo deseamos específicamente. Una opción sería, habilitar la visualizacion de la llave cuando nos conectamos por ssh con un servidor con la opcion adicional, de forma que el comando total nos queda asi:
ssh root@ssh-server -o VisualHostKey=yes
Con lo que nos mostrará el randomart de la clave que estamos usando para conectarnos.
Pero... y si quisiera usar el randomart para comparar claves, perdidas, danadas o simplemente confundidas?
Bueno, el servidor podría convertir las llaves públicas existentes en el archivo know_host así:
ssh-keygen -lvf ~/.ssh/known_hosts---> ESTO ME GUSTA !!!
y podríamos comparar esta salida con el resultado en nuestro cliente con:
ssh-keygen -lv ---> Y ESTO TAMBIEN :-)
ACTUALIZACION 16.05.2018
Tuve que configurarme un laptop nuevo para acceder a estos servidores desde la casa, pero cuando quise enviar su clave con ssh-copy-id y me pidió la contrasena de administrador que no tenia...
Tanto uso el sistema de llaves para ssh, que en un(os) servidores se me olvidó la contrasena.
Claro, siempre podía logearme en el otro computador, por lo que desde este, importé la clave asi:
https://victorhckinthefreeworld.com/2016/01/28/transferir-llaves-ssh-de-un-pc-a-otro-en-gnulinux/
Si hemos perdido la clave publica, pero conservamos la privada. Podemos "recrearla" con el comando:
ssh-keygen -y -f ~/.ssh/id_rsa > ~/.ssh/id_rsa.pub
ACTUALIZACION 14:11:2018
Cuando creamos el par de claves, ssh-keygen nos va a mostrar una salida artistica de la llave que se llama randomart.
Este dibujito, no lo volveremos a ver nunca mas si no lo deseamos específicamente. Una opción sería, habilitar la visualizacion de la llave cuando nos conectamos por ssh con un servidor con la opcion adicional, de forma que el comando total nos queda asi:
ssh root@ssh-server -o VisualHostKey=yes
Con lo que nos mostrará el randomart de la clave que estamos usando para conectarnos.
Pero... y si quisiera usar el randomart para comparar claves, perdidas, danadas o simplemente confundidas?
Bueno, el servidor podría convertir las llaves públicas existentes en el archivo know_host así:
ssh-keygen -lvf ~/.ssh/known_hosts---> ESTO ME GUSTA !!!
y podríamos comparar esta salida con el resultado en nuestro cliente con:
ssh-keygen -lv ---> Y ESTO TAMBIEN :-)
ACTUALIZACION 16.05.2018
Tuve que configurarme un laptop nuevo para acceder a estos servidores desde la casa, pero cuando quise enviar su clave con ssh-copy-id y me pidió la contrasena de administrador que no tenia...
Tanto uso el sistema de llaves para ssh, que en un(os) servidores se me olvidó la contrasena.
Claro, siempre podía logearme en el otro computador, por lo que desde este, importé la clave asi:
- pasar la clave publica .pub al computador que sí permite logearse (sin contrasena, pues tiene clave ssh)
- Ejecutar en consola, dentro del directorio donde esta la clave:
cat id_rsa.pub | ssh root@servidor-obj 'cat >> .ssh/authorized_keys && echo "Key copied"' - este comando manda la salida de cat, al archivo .ssh/authorized_keys de el servidor-obj deseado.
https://victorhckinthefreeworld.com/2016/01/28/transferir-llaves-ssh-de-un-pc-a-otro-en-gnulinux/
*********************************
valido para mac y linux:
ssh-keygen -t rsa -b 4096
-- algunos anaden -f ~/.ssh/id_rsa , si no lo haces, igual el programa preguntará el nombre y el camino del archivo. Si tampoco escribes algo especial, entonces tomará el valor por defecto arriba escrito.
-- también preguntará por una "paraphrase" que es una contraseña adicional para la clave. Personalmente pienso que es muy importante, puesto que si alguien se apropiara de la clave tendría fácil acceso a todos los ámbitos donde la clave funciona. Con una paraphrase tendría también que tener esta para cualquier conexión.
Este comando generara dos claves: id_rsa und id_rsa.pub en el directorio .ssh raiz del usuario.
La .pub es la clave pública, que se copiará en los servidores dentro del archivo "know_host" y la otra es la privada, que debe permanecer secreta en este directorio donde fué generada.
Hasta aqui con la parte cliente. Ahora debemos poner la clave pública entre las claves ssh aceptadas por el servidor. Para esto usaremos ssh-copy-id
ssh-copy-id root@server
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/Users/user/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
user@server's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'user@server'"
and check to make sure that only the key(s) you wanted were added.
-- OJO SOBRE EL USUARIO -- si queremos dar acceso a otro userx al servidor ssh hay que ejecutar:
ssh-copy-id userx@server desde el computador del userx y en su cuenta. Teniendo el userx ya una cuenta en el servidor.
--- NOTA IMPORTANTE ---
Si por alguna razon ssh-copy-id no funcionara, se vale tambien copiar (por ftp/filezilla, scp, ssh-->vim, etc.) la clave .pub del cliente /root/.ssh/id_rsa.pub en el servidor en el archivo "host_allow" /root/.ssh/authorized_keys
jueves, 5 de enero de 2017
Reseteando la contrasena de MariaDB en Linux Devuan (una variante Debian)
Update 09.01.17
He encontrado el origen del problema:
al detener el servicio mysql con service mysql stop, he iniciar en modo seguro con deb-maint. Puedo ver las tablas de los usuarios. Alli aparece lo siguiente;
+-----------+---------------------+---------------------+
| host | user | password |
+-----------+---------------------+---------------------+
| localhost | root | * Blablabla-foobar
| server | root | * *Blablabla-foobar |
| 127.0.0.1 | root | * *Blablabla-foobar |
| ::1 | root | * *Blablabla-foobar |
| localhost | debian-sys-maint | * *Blablabla-foobar |
| % | user01 | |
| % | root | * *Blablabla-foobar |
+-----------+----------------------+---------------------+
el problema esta en el "hostname", para que funcione debes poner el "localhost" asi:
mysql -u root -h localhost -p
Pero mucho cuidado, pues esto no va a funcionar en la misma sesion, incluso tampoco con el mismo servicio, pues el modo seguro tambien se puede ejecutar "sin red" con lo que localhost tampoco funciona!
05.01.17 04:57
Si bien la contrasena de SQL no debería significar un problema grave, ya que es mas que seguro que tenemos la contrasena de root, por experiencia no resulta tan facil. Una cantidad de problemas se derivan de las versiones de SQL como de los systemas operativos que los albergan.
No estoy tratando aqui de competir contra las instrucciones de Oracle o MDB. Sino que documento aqui como resolví mis propios problemas, para tenerlo a mano en caso de volver a necesitarlo y ademas que si a alguien le sirven, me alegra.
service mysql stop
mysqld_safe --skip-grant-tables --skip-networking &
mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 4
Server version: 10.0.28-MariaDB-0+deb8u1 (Debian)
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('new_password');
ERROR 1131 (42000): You are using MariaDB as an anonymous user and anonymous users are not
Ujum... entonces pruebo toda la session desde el comienzo con root:
service mysql stop
mysqld_safe --skip-grant-tables --skip-networking &
mysql -u root
FLUSH PRIVILEGES;
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('new_password');
ERROR 1131 (42000): You are using MariaDB as an anonymous user and anonymous users are not allowed to change passwords
???
Parece que tengo un terrible problema...
Bueno, la verdadera razon de ese problema parece residir en la configuracion original de mysql
bastante interesante es que el comando...
mysql_secure_installation
tambien me devuelve ese error:
Enter current password for root (enter for none):
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
lentamente estoy pensando en reinstalar todo, pero antes un par de tips interesantes que también encontré:
1.- hay un usuario debian-sys-maint que tiene privilegios elevados y puede ejecutar y configurar bases de datos, su contrasena es un texto aleatorio guardado en el archivo
/etc/mysql/debian.cnf
con él te puedes logear y resetear contrasenas
2.- Con el usuario debian-sys-maint (quizas también con otro) puedes visualizar los usuarios configurados de mysql.
select host, user, password from mysql.user;
en esta tabla puedes ver "encriptadas" las contrasenas, esto puede ser util a pesar de todo para estar seguro de los nombres de usuario, saber si un usuario con contrasena desconocida/olvidada tiene la misma de uno que conozcamos, o para constatar si nuestro cambio o reseteo de contrasenas esta funcionando.
3.- El comando: update mysql.user set password=password('tu-contrasena') where user='root';
sirve para resetear contrasenas.
He encontrado el origen del problema:
al detener el servicio mysql con service mysql stop, he iniciar en modo seguro con deb-maint. Puedo ver las tablas de los usuarios. Alli aparece lo siguiente;
+-----------+---------------------+---------------------+
| host | user | password |
+-----------+---------------------+---------------------+
| localhost | root | * Blablabla-foobar
| server | root | * *Blablabla-foobar |
| 127.0.0.1 | root | * *Blablabla-foobar |
| ::1 | root | * *Blablabla-foobar |
| localhost | debian-sys-maint | * *Blablabla-foobar |
| % | user01 | |
| % | root | * *Blablabla-foobar |
+-----------+----------------------+---------------------+
el problema esta en el "hostname", para que funcione debes poner el "localhost" asi:
mysql -u root -h localhost -p
Pero mucho cuidado, pues esto no va a funcionar en la misma sesion, incluso tampoco con el mismo servicio, pues el modo seguro tambien se puede ejecutar "sin red" con lo que localhost tampoco funciona!
05.01.17 04:57
Si bien la contrasena de SQL no debería significar un problema grave, ya que es mas que seguro que tenemos la contrasena de root, por experiencia no resulta tan facil. Una cantidad de problemas se derivan de las versiones de SQL como de los systemas operativos que los albergan.
No estoy tratando aqui de competir contra las instrucciones de Oracle o MDB. Sino que documento aqui como resolví mis propios problemas, para tenerlo a mano en caso de volver a necesitarlo y ademas que si a alguien le sirven, me alegra.
service mysql stop
mysqld_safe --skip-grant-tables --skip-networking &
mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 4
Server version: 10.0.28-MariaDB-0+deb8u1 (Debian)
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('new_password');
ERROR 1131 (42000): You are using MariaDB as an anonymous user and anonymous users are not
Ujum... entonces pruebo toda la session desde el comienzo con root:
service mysql stop
mysqld_safe --skip-grant-tables --skip-networking &
mysql -u root
FLUSH PRIVILEGES;
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('new_password');
ERROR 1131 (42000): You are using MariaDB as an anonymous user and anonymous users are not allowed to change passwords
???
Parece que tengo un terrible problema...
Bueno, la verdadera razon de ese problema parece residir en la configuracion original de mysql
bastante interesante es que el comando...
mysql_secure_installation
tambien me devuelve ese error:
Enter current password for root (enter for none):
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
lentamente estoy pensando en reinstalar todo, pero antes un par de tips interesantes que también encontré:
1.- hay un usuario debian-sys-maint que tiene privilegios elevados y puede ejecutar y configurar bases de datos, su contrasena es un texto aleatorio guardado en el archivo
/etc/mysql/debian.cnf
con él te puedes logear y resetear contrasenas
2.- Con el usuario debian-sys-maint (quizas también con otro) puedes visualizar los usuarios configurados de mysql.
select host, user, password from mysql.user;
en esta tabla puedes ver "encriptadas" las contrasenas, esto puede ser util a pesar de todo para estar seguro de los nombres de usuario, saber si un usuario con contrasena desconocida/olvidada tiene la misma de uno que conozcamos, o para constatar si nuestro cambio o reseteo de contrasenas esta funcionando.
3.- El comando: update mysql.user set password=password('tu-contrasena') where user='root';
sirve para resetear contrasenas.
martes, 13 de diciembre de 2016
Experiencias con el Chat de solo texto Profanity
Sí yo sé: Adium y Pidgin son clase!. Pero mi Mac no es una nave voladora que digamos. Para evitar los peges, he optado por sacar lo superfluo, entre ellos Adium.
Y es que en mi trabajo usamos un chat XMPP con el que intercambiamos texto, aunque raramente smiles y aun mas raramente documentos y menos fotos y otras multimedia. Tampoco usamos otros protocolos como gogle chat, skype, messenger o que se yo que mas que el Adium soporte.
La verdad que para ese rudimentario intercambio de texto esta el Adium no solo sobrados, sino que tambien, infrautilizado.
Por esto, decidí ponerme a buscar algo mas liviano y encontré a Profanity. Un cliente xmpp en modo consola, liviano y multiplataforma del cual quede enamorado a primera vista.
Como cualquier aplicacion de consola, hay que escribir comandos, recordarlos y saber usarlos. Por esto, y para que no se me olviden los útiles he decidido escribir un Post, con la esperanza de reutilizar el conocimiento y con que quizas tambien a otros le sirva.
Buscar ayuda:
/help <<----- ensena una clasificacion de los comandos segun tema
/help commands <<------- ensena todos los comandos
/help comandoespecifico <<--------- muestra la ayuda para ese comando especifico
/help navegation <<---- tips de navegacion
Interface:
/beep on/off <<----- Activa / desactiva las notificaciones
/history <<--- Activa el historial (como en bash)
/clear <<--- limpiar
/flash on/off <<--- destella cuando hay un mensaje
/intype on/off <<-- dice si alguien tipea
Estatus
/away <<------ Ausente
/xa mensaje <<------ largamente ausente (extended away) con mensaje
Ventanas
/win 3 <<---- se va a la ventana y al chat #3
alt + pgd down/up <<----- ver mas abajo o arriba de la ventana
F1... Fx <<--- ventanas 1 hasta x
Chats
/close 2 <<--- cierra la ventana 2
/join chatname <<----- entra en chatname
/msg "alguien" hola <<--- manda el mensaje
/autoconnect usuario.muestra@chat.com <<------- conecta automaticamente a usuario.muestra al iniciar
/roster add fulanito@chat.com <<-- agrega a fulanito a tus amigos
/roster remove fulanito@chat.com <<-- lo saca
Control
/quit << salir
/script run nombredelscript <<------
ejecuta un script que debe estar guardado en ~/.local/profanity/scripts y que utiliza los comandos de la consola de profanity como lenguaje. Muy útil para configuraciones previas, para mi por ejemplo me sirvio para unirme a todos los chat al empezar la sesion poniendo en el script "inicio" los siguiente
/join chat1
/join chat2
Archivos de configuracion:
EN MAC, tiene profanity 2 directorios importantes:
~/.config/profanity
... profrc <<--- tiene casi el mismo contenido de un tema, con algunas variaciones
~/.local/profanity
Los Temas (theme)
son una cosa bien importante como poderosa. Podemos listar los temas disponibles con
/theme list
para cambiarlo basta:
/theme load nombredeltema
los temas disponibles se deben guardar en:
~/.config/profanity/themes
aunque los del systema estan en la instalacion del programa:
/usr/local/cellar/profanity/0.5.0/share/profanity/theme
si no encuentras nada alli, es porque es la carpeta para tus temas y no para los que vienen por defecto.
Se pueden bajar temas desde el git del autor:
https://github.com/boothj5/profanity/tree/master/themes
puedes probarlos con "theme load" y comenzar a editar el que mas te guste.
los colores aceptados son:
Y es que en mi trabajo usamos un chat XMPP con el que intercambiamos texto, aunque raramente smiles y aun mas raramente documentos y menos fotos y otras multimedia. Tampoco usamos otros protocolos como gogle chat, skype, messenger o que se yo que mas que el Adium soporte.
La verdad que para ese rudimentario intercambio de texto esta el Adium no solo sobrados, sino que tambien, infrautilizado.
Por esto, decidí ponerme a buscar algo mas liviano y encontré a Profanity. Un cliente xmpp en modo consola, liviano y multiplataforma del cual quede enamorado a primera vista.
Como cualquier aplicacion de consola, hay que escribir comandos, recordarlos y saber usarlos. Por esto, y para que no se me olviden los útiles he decidido escribir un Post, con la esperanza de reutilizar el conocimiento y con que quizas tambien a otros le sirva.
Buscar ayuda:
/help <<----- ensena una clasificacion de los comandos segun tema
/help commands <<------- ensena todos los comandos
/help comandoespecifico <<--------- muestra la ayuda para ese comando especifico
/help navegation <<---- tips de navegacion
Interface:
/beep on/off <<----- Activa / desactiva las notificaciones
/history <<--- Activa el historial (como en bash)
/clear <<--- limpiar
/flash on/off <<--- destella cuando hay un mensaje
/intype on/off <<-- dice si alguien tipea
Estatus
/away <<------ Ausente
/xa mensaje <<------ largamente ausente (extended away) con mensaje
/chat << --- disponible para chatear (ansprechbar)
/online <<--- pone el estatus en verde y lo hace activo (verfugbar)
/dnd <<--- do not disturb, o en otras palabras nojo.../gone Ventanas
/win 3 <<---- se va a la ventana y al chat #3
alt + pgd down/up <<----- ver mas abajo o arriba de la ventana
F1... Fx <<--- ventanas 1 hasta x
Chats
/close 2 <<--- cierra la ventana 2
/join chatname <<----- entra en chatname
/msg "alguien" hola <<--- manda el mensaje
/autoconnect usuario.muestra@chat.com <<------- conecta automaticamente a usuario.muestra al iniciar
/roster add fulanito@chat.com <<-- agrega a fulanito a tus amigos
/roster remove fulanito@chat.com <<-- lo saca
Control
/quit << salir
/script run nombredelscript <<------
ejecuta un script que debe estar guardado en ~/.local/profanity/scripts y que utiliza los comandos de la consola de profanity como lenguaje. Muy útil para configuraciones previas, para mi por ejemplo me sirvio para unirme a todos los chat al empezar la sesion poniendo en el script "inicio" los siguiente
/join chat1
/join chat2
Archivos de configuracion:
EN MAC, tiene profanity 2 directorios importantes:
~/.config/profanity
... profrc <<--- tiene casi el mismo contenido de un tema, con algunas variaciones
~/.local/profanity
Los Temas (theme)
son una cosa bien importante como poderosa. Podemos listar los temas disponibles con
/theme list
para cambiarlo basta:
/theme load nombredeltema
los temas disponibles se deben guardar en:
~/.config/profanity/themes
aunque los del systema estan en la instalacion del programa:
/usr/local/cellar/profanity/0.5.0/share/profanity/theme
si no encuentras nada alli, es porque es la carpeta para tus temas y no para los que vienen por defecto.
Se pueden bajar temas desde el git del autor:
https://github.com/boothj5/profanity/tree/master/themes
puedes probarlos con "theme load" y comenzar a editar el que mas te guste.
los colores aceptados son:
whitebold_whiteblackbold_black
yellowbold_yellowbold_greengreenbluebold_blueredbold_red
cyanbold_cyanmagentabold_magenta
el orden es según mi lógica como armonizan mejorjueves, 1 de diciembre de 2016
instalaciones de paquetes de software con github
desde que existe github existe con él una nueva alternativa para la instalacion de software que debemos manejar exactamente bien como en el caso de yum, apt-get, aptitude y demas.
la instalacion con github tiene la ventaja de no sobreescribir todos los paquetes sino que analiza primero las alternativas.
Esto puede ser util cuando trabajamos con un software de codigo abierto que editamos a nuestro gusto y del cual queremos editar solamente los archivos que nosotros no editamos.
Basicamente el comando git, copia o "Clona" el contenido del repositorio Web de Github en nuestra computadora objeto.
El siguiente comando clonará el depositorio de cowsay en un directorio llamado "cowsay" en el directorio activo donde nos encontremos para
git clone git://github.com/schacon/cowsay
El resto dependerá de la forma en que este software se instale, para el caso de cowsay, se ejecuta despues un script install.sh y ya.
Un articulo mucho mas extenso sobre el tema, el cual inspiró este minihow, se puede encontrar en
https://www.lifewire.com/installing-software-using-git-3993572
la instalacion con github tiene la ventaja de no sobreescribir todos los paquetes sino que analiza primero las alternativas.
Esto puede ser util cuando trabajamos con un software de codigo abierto que editamos a nuestro gusto y del cual queremos editar solamente los archivos que nosotros no editamos.
Basicamente el comando git, copia o "Clona" el contenido del repositorio Web de Github en nuestra computadora objeto.
El siguiente comando clonará el depositorio de cowsay en un directorio llamado "cowsay" en el directorio activo donde nos encontremos para
git clone git://github.com/schacon/cowsay
El resto dependerá de la forma en que este software se instale, para el caso de cowsay, se ejecuta despues un script install.sh y ya.
Un articulo mucho mas extenso sobre el tema, el cual inspiró este minihow, se puede encontrar en
https://www.lifewire.com/installing-software-using-git-3993572
jueves, 20 de octubre de 2016
el comando find
el comando find se diferencia del comando grep en que el primero busca ficheros en el directorio mientras que el segundo busca cadenas de texto dentro de archivos
find puede encontrar directorios o archivos con la opcion
-type d
-type f
. significa directorio activo
/ significa directorio raiz
y por supuesto todas sus variantes como /home/desktop/etcymas
-name archivo.txt
pero tambien sirvern aqui los comodines o wildcards *
tambien tenemos la opcion ignora el nombre para
-iname archivo.txt
donde find no va a encontrar este nombre
con los comodines entonces podemos encontrar todos los archivos de scripts de pyton ignorando los que pertenecen a test asi:
find / -type f -name *.py -iname test*.py
find tambien nos permite encontrar segun permisos
find . -perm 777 -print
./logfile.001
find puede encontrar directorios o archivos con la opcion
-type d
-type f
. significa directorio activo
/ significa directorio raiz
y por supuesto todas sus variantes como /home/desktop/etcymas
-name archivo.txt
pero tambien sirvern aqui los comodines o wildcards *
tambien tenemos la opcion ignora el nombre para
-iname archivo.txt
donde find no va a encontrar este nombre
con los comodines entonces podemos encontrar todos los archivos de scripts de pyton ignorando los que pertenecen a test asi:
find / -type f -name *.py -iname test*.py
find tambien nos permite encontrar segun permisos
find . -perm 777 -print
./logfile.001
Virtualizacion con KVM
No voy a discutir porque KVM y no XEN o VMWare. He tenido que usar KVM!
La interfaz me ha parecido espartana como un kernel solitario de linux en su version mas primitiva.
No es tan verdad, puesto que kvm cuenta con un interprete de comando llamado virsh que es bastante poderoso.
Pero cuando te acostumbras al clickliclicki con XEN o VMWare, y tienes que usar KVM te parece un viaje en la historia al pasado.
El manejo de KVM es casi obligatorio a traves de ssh y la consola virsh, porque el unico manager con interface para clientes corre solo en linux de manera nativa. Pero tampoco es tan malo: con una maquina virtual local se puede installar un linux rudimentario que corra puro virt-manager en windows, y en mac hay algunas recetas para brew que con sudor sangre y lagrimas funcionaran despues de algunos dias :-)
La instalacion en Ubuntu es mas o menos asi
La interfaz me ha parecido espartana como un kernel solitario de linux en su version mas primitiva.
No es tan verdad, puesto que kvm cuenta con un interprete de comando llamado virsh que es bastante poderoso.
Pero cuando te acostumbras al clickliclicki con XEN o VMWare, y tienes que usar KVM te parece un viaje en la historia al pasado.
El manejo de KVM es casi obligatorio a traves de ssh y la consola virsh, porque el unico manager con interface para clientes corre solo en linux de manera nativa. Pero tampoco es tan malo: con una maquina virtual local se puede installar un linux rudimentario que corra puro virt-manager en windows, y en mac hay algunas recetas para brew que con sudor sangre y lagrimas funcionaran despues de algunos dias :-)
La instalacion en Ubuntu es mas o menos asi
sudo apt install qemu-kvm libvirt-bin
sudo apt install virtinst
el usuario que va a trabajar con libvirtd debe pertenecer al grupo, para saber si esta
bastara
groups username
si libvirtd no esta en la lista deberemos agregarlo con:
sudo adduser username libvirtd
Otra Guia mas de grep
bueno, no quiero reinventar el fuego: esta guia la he escrito para mi mismo aunque si a alguien le sirve me agradará saberlo!
Grep es un comando Unix que sirve para buscar cadenas de texto en archivos.
basicamente funciona así:
grep cadenaabuscar archivoendondesebusca
si la cadena es larga y contiene espacios se puede usar ' ':
grep 'cadena a buscar' archivoendondebusca
si queremos que grep nos diga solo las linias que empiezan con una cadena:
grep '^cadena con la que debe iniciar la linia' archivo.txt
si queremos que a grep no le importen las mayusculas o las minusculas usamos -i
grep -i CadenAaBuscar archivo.txt
si queremos que grep busque una palabra en cualquier lugar de la linea usamos $
grep 'palabra$' archivo.txt
se diferencia de
grep 'palabra' archivo.txt --> en que este segundo comando buscará la palabra aunque este metida en otra palabra asi: parangacutitidimicuaropalabraparangacutitidimicuaro
si queremos que grep nos ensene las liniea donde NO ESTA una cadena usaremos -vi
grep -vi 'cadenaquenoquiero' archivo.txt
tambien podemos decirle a grep que busque en un grupo de archivos cuyo nombre empieza con asi "arch" por ejemplo, asi:
grep 'buscaesto" arch*
y el nos dara un resultado diciendo donde lo encontro y que:
archivo1.txt:buscaestoaqui
archivo2.txt:buscaestoalla
y si solo queremos que grep nos diga en que archivo esta podemos usar -l (list) que ademas podemos combinar con las otras y hacer un -vil
grep -l '3' arch*
archivo1.txt
archivo2.txt
podemos tambien decirle a grep que nos ensene una linea antes o despues de la liniea encontrada con grep -C cuantaslinias -i "cadena" archivo.txt
... cuantaslinias
liniadearriba
cadena
liniadeabajo
... cuantaslinias
claro, con numeros:
grep -C 2 -i "cadena" archivo.txt
ah, apropósito tambien sirven las comillas dobles "" en lugar de simples ''
tambien podemos decirle a grep que consiga las lineas que contienen caracteres entre una secuencia, como desde el 0 al 5 asi:
grep [0-5] archivo.txt
linea con un 2
linea con un 4
1 linea
3 linea
la linia con un 6 no saldrá
si solo queremos que grep encuentre las lineas que comienzan con estos numeros usamos ^
grep [^0-5] archivo.txt
1 linea
3 linea
y las otras dos que no comienzan con los numeros de las secuencia buscada no saldran
grep tambien se entiende bien con directorios, asi si estamos en un directorio que contiene otro llamado "carpeta" podemos decirle a grep
grep 'cadena' carpeta/*
y si queremos una busqueda recursiva (que incluya subcarpetas) podemos usar -r
grep -r cadena carpeta/*
la opcion -n nos permitira ver el numero de línia donde esta la cadena
~\> grep -n [0-3] test.txt
2:testing 1
3:Testing 2
4:TesT 3
Uno muy útil, mostrar el contenido de un fichero omitiendo las linieas comentadas. Por ejemplo para apache.conf etc:
grep -v ^# autofs.conf
quitar las lineas vacias:
grep . archivo.txt
y quitar las linias comentadas y las vacias:
grep -v ^# archivo.txt | grep .
comparar dos ficheros: mejor que grep en este caso te recomiendo sdiff (super-diferencias, en realidad sidebysidediff) que te muestra los resultados ordenadamente en una tablita...
sdiff archivo1.txt archivo2.txt
aparte de sdiff tambien existe un diff, un poco mas primitivo que el primero, aunque en algunos casos podria ser útil, la sintaxis es la misma
Aqui una tablita util de opciones de grep:
esta tablita me la tome de:
http://www.prontosystems.org/tux/grep
Crear una script condicional usando grep:
#!/bin/bash
# Script que comprueba la existencia de un Driver
# en conjuncion con Munki se puede usar para instalar el mismo si no esta
if kextstat | grep -q "com.asix.driver.ax88179-178a";
then
# Driver vorhanden
touch /Users/Shared/found_kesing_driv.txt
exit 1
else
# Driver existiert NIX
touch /Users/Shared/NOT-found_kesing_driv.txt
exit 0
fi
si deseamos que el script funcione a la inversa entonces agregamos ! despues de if
la "q" sirve para que grep no nos devuelva las lineas donde encontró algo. Ideal para Scripts.
Grep es un comando Unix que sirve para buscar cadenas de texto en archivos.
basicamente funciona así:
grep cadenaabuscar archivoendondesebusca
si la cadena es larga y contiene espacios se puede usar ' ':
grep 'cadena a buscar' archivoendondebusca
si queremos que grep nos diga solo las linias que empiezan con una cadena:
grep '^cadena con la que debe iniciar la linia' archivo.txt
si queremos que a grep no le importen las mayusculas o las minusculas usamos -i
grep -i CadenAaBuscar archivo.txt
si queremos que grep busque una palabra en cualquier lugar de la linea usamos $
grep 'palabra$' archivo.txt
se diferencia de
grep 'palabra' archivo.txt --> en que este segundo comando buscará la palabra aunque este metida en otra palabra asi: parangacutitidimicuaropalabraparangacutitidimicuaro
si queremos que grep nos ensene las liniea donde NO ESTA una cadena usaremos -vi
grep -vi 'cadenaquenoquiero' archivo.txt
tambien podemos decirle a grep que busque en un grupo de archivos cuyo nombre empieza con asi "arch" por ejemplo, asi:
grep 'buscaesto" arch*
y el nos dara un resultado diciendo donde lo encontro y que:
archivo1.txt:buscaestoaqui
archivo2.txt:buscaestoalla
y si solo queremos que grep nos diga en que archivo esta podemos usar -l (list) que ademas podemos combinar con las otras y hacer un -vil
grep -l '3' arch*
archivo1.txt
archivo2.txt
podemos tambien decirle a grep que nos ensene una linea antes o despues de la liniea encontrada con grep -C cuantaslinias -i "cadena" archivo.txt
... cuantaslinias
liniadearriba
cadena
liniadeabajo
... cuantaslinias
claro, con numeros:
grep -C 2 -i "cadena" archivo.txt
ah, apropósito tambien sirven las comillas dobles "" en lugar de simples ''
tambien podemos decirle a grep que consiga las lineas que contienen caracteres entre una secuencia, como desde el 0 al 5 asi:
grep [0-5] archivo.txt
linea con un 2
linea con un 4
1 linea
3 linea
la linia con un 6 no saldrá
si solo queremos que grep encuentre las lineas que comienzan con estos numeros usamos ^
grep [^0-5] archivo.txt
1 linea
3 linea
y las otras dos que no comienzan con los numeros de las secuencia buscada no saldran
grep tambien se entiende bien con directorios, asi si estamos en un directorio que contiene otro llamado "carpeta" podemos decirle a grep
grep 'cadena' carpeta/*
y si queremos una busqueda recursiva (que incluya subcarpetas) podemos usar -r
grep -r cadena carpeta/*
la opcion -n nos permitira ver el numero de línia donde esta la cadena
~\> grep -n [0-3] test.txt
2:testing 1
3:Testing 2
4:TesT 3
Uno muy útil, mostrar el contenido de un fichero omitiendo las linieas comentadas. Por ejemplo para apache.conf etc:
grep -v ^# autofs.conf
quitar las lineas vacias:
grep . archivo.txt
y quitar las linias comentadas y las vacias:
grep -v ^# archivo.txt | grep .
comparar dos ficheros: mejor que grep en este caso te recomiendo sdiff (super-diferencias, en realidad sidebysidediff) que te muestra los resultados ordenadamente en una tablita...
sdiff archivo1.txt archivo2.txt
aparte de sdiff tambien existe un diff, un poco mas primitivo que el primero, aunque en algunos casos podria ser útil, la sintaxis es la misma
Aqui una tablita util de opciones de grep:
| Option | Beschreibung |
|---|---|
| -r | Setze die Suche rekursiv durch alle Unterverzeichnisse fort. Funktioniert nur bei der Verwendung von Wildcards einwandfrei |
| -c | Anzeige der Anzahl Zeilen, in denen das Muster gefunden wurde |
| -i | Groß- und Kleinschreibung werden nicht unterschieden |
| -l | Nur Anzeige der Namen der Dateien, in denen das Muster gefunden wurde |
| -n | Zeigt die Zeilennummer an, in der das Muster gefunden wurde |
| -s | Unterdrückt die Fehlerausgaben (Standardfehler); sinnvoll in Skripten |
| -v | Zeigt alle Zeilen an, die das Muster nicht enthalten |
| -w | Das Suchmuster muss ein einzelnes Wort sein (also kein Bestandteil eines anderen Wortes) |
| -A [n] | Zeigt »n« Zeilen an, die der Zeile mit dem Muster folgen |
| -B [n] | Zeigt »n« Zeilen an, die vor der Zeile mit dem Muster liegen |
| --color=auto | Hebt das gesuchte Muster farblich hervor |
esta tablita me la tome de:
http://www.prontosystems.org/tux/grep
Crear una script condicional usando grep:
#!/bin/bash
# Script que comprueba la existencia de un Driver
# en conjuncion con Munki se puede usar para instalar el mismo si no esta
if kextstat | grep -q "com.asix.driver.ax88179-178a";
then
# Driver vorhanden
touch /Users/Shared/found_kesing_driv.txt
exit 1
else
# Driver existiert NIX
touch /Users/Shared/NOT-found_kesing_driv.txt
exit 0
fi
si deseamos que el script funcione a la inversa entonces agregamos ! despues de if
la "q" sirve para que grep no nos devuelva las lineas donde encontró algo. Ideal para Scripts.
LibreOffice remplaza dos guiones por uno
a veces cuando tengo que escribir un documento sobre el shell o con mezclas de ingles o aleman, el corrector automatico de LibreOffice me molesta: corrige por ejemplo el comando
virsh list --all
en este otro: virsh list -all
que por supuesto no es para nada lo mismo,.
Para quitarlo debes ir al menu --> format --> autocorrect --> options
y ver lo que queremos configurar "mientras tipeas" o "
Tambien se puede desactivar la autocorreccion "while typing"
las opciones tambien puedes ser una opcion... aunque para mi problema con dos -- que se convierten en uno, habia un "hack" especial:
menu --> format --> autocorrect --> option --> replace dashes
virsh list --all
en este otro: virsh list -all
que por supuesto no es para nada lo mismo,.
Para quitarlo debes ir al menu --> format --> autocorrect --> options
y ver lo que queremos configurar "mientras tipeas" o "
Tambien se puede desactivar la autocorreccion "while typing"
las opciones tambien puedes ser una opcion... aunque para mi problema con dos -- que se convierten en uno, habia un "hack" especial:
menu --> format --> autocorrect --> option --> replace dashes
Creando secuencias con Shell, seq , echo, jot...
seq puede crear secuencias numericas crecientes y decrecientes con diferentes intervalos, la forma mas simple seria:
seq 5
1
2
3
4
5
si queremos la secuencia decreciente
seq 5 1
5
4
3
2
1
si queremos rellenos con ceros
seq -w 5 1
5
4
3
2
1
¡no pasó nada! -- noo, si pasa, pero aqui no hay ceros que rellenar, prueba
seq -w 10 1
o
seq -w 100 1 ó tambien seq -w 100
y aqui el último numero de la secuencia será 001
ahora los intervalos...
los intervalos standard son de unidad. Si queremos intervalos diferentes tenemos que definir el inicio, intervalo y fin, asi:
seq 1 0.5 10
o decreciente con
seq 10 0.5 1
aha! aqui seq no hace nada y nos dice:
seq: needs negative decrement
que es absolutamente lógico pues le estamos pidiendo a seq que nos haga una secuencia decremental, y seq sólo suma el intervalo, por lo que tenemos que darle a seq un intervalo negativo, asi
seq 10 -0.5 1 si nos funcionará
las opciones -s y -t tambien nos pueden ser muy útiles
seq -s , -t ENDSEQ 10 -0.5 1
10,9.5,9,8.5,8,7.5,7,6.5,6,5.5,5,4.5,4,3.5,3,2.5,2,1.5,1,ENDSEQ
lo que podria servir por ejemplo para rellenar matrices o crear sucesiones.
Y para terminar aun nos queda la opcion -f o "format" que va a definir si los números se presentarán como estandard (%g), exponencial o notacion cientifica(%e), o con punto decimal y 6 posiciones decimales(%f)
prueba seq -f %g con %e y f% y veras estos formatos mas claramente, pero la fuerza de -f no radica exactamente en estos 3 formatos, sino en los formatos adicionales que se pueden crear a traves de estos. Y es que -f tambien puede ser "archivo%02g.txt" o "logfile.%03g" asi
~\> seq -f "logfile.%03g" 5
logfile.001
logfile.002
logfile.003
logfile.004
logfile.005
con lo que podemos usar seq para crear archivos por ejemplo asi:
touch $(seq -f "logfile.%03g" 5)
o para borrarlos, o crear directorios, etc.
SECUENCIAS CON JOT
SECUENCIAS CON ECHO
echo {1..9}
1 2 3 4 5 6 7 8 9
echo {5..1}
5 4 3 2 1
en este sentido es echo un poco mas poderoso que seq y jot ya que estas secuencias pueden ser tambien alfabeticas, como
echo {a..z}
echo {A..Z}
y reversas:
echo {z..a} a asi...
pero estas secuencias estaran siempre en la misma linea (a no ser que se acabe la pantalla entonces salta a la siguiente linea), y si quisieramos que los numeros esten uno bajo el otro necesitaremos a xargs asi
echo {1..10} | xargs -n1
cosa que podria parecer molesta depender de un segundo comando para esta opcion, aunque si lo miramos asi
echo {1..9} | xargs -n3
echo {a..y} | xargs -n5
tenemos como resultado unas bonitas matrices
pero la salida de { .. } la podemos utilizar en Unix de muchas otras maneras mas alla de echo, ya que echo es solo un repetidor que saca cosas por la salida estandar stdout o por otra dirigida con direccionamientos > o pipes
asi podemos directamente crear el efecto de arriba en ~\> seq -f "logfile.%03g" 5
con:
touch logfile.00{1..5}
crear directorios:
md directorio_{a..z} ó sino tambien md {a..z}_directorio
con XARGS podemos
cambiar derechos de grupos de usuarios en todas las carpetas dentro del directorio listado:
o lo que seria aún mejor, cambiar los derechos de sólo algunos directorios que cumplan con alguna condición como los que comienzen con "a"
ls a* | xargs sudo chgrp wheel
o filtrarlo con find:
find d* -*k-z
seq 5
1
2
3
4
5
si queremos la secuencia decreciente
seq 5 1
5
4
3
2
1
si queremos rellenos con ceros
seq -w 5 1
5
4
3
2
1
¡no pasó nada! -- noo, si pasa, pero aqui no hay ceros que rellenar, prueba
seq -w 10 1
o
seq -w 100 1 ó tambien seq -w 100
y aqui el último numero de la secuencia será 001
ahora los intervalos...
los intervalos standard son de unidad. Si queremos intervalos diferentes tenemos que definir el inicio, intervalo y fin, asi:
seq 1 0.5 10
o decreciente con
seq 10 0.5 1
aha! aqui seq no hace nada y nos dice:
seq: needs negative decrement
que es absolutamente lógico pues le estamos pidiendo a seq que nos haga una secuencia decremental, y seq sólo suma el intervalo, por lo que tenemos que darle a seq un intervalo negativo, asi
seq 10 -0.5 1 si nos funcionará
las opciones -s y -t tambien nos pueden ser muy útiles
seq -s , -t ENDSEQ 10 -0.5 1
10,9.5,9,8.5,8,7.5,7,6.5,6,5.5,5,4.5,4,3.5,3,2.5,2,1.5,1,ENDSEQ
lo que podria servir por ejemplo para rellenar matrices o crear sucesiones.
Y para terminar aun nos queda la opcion -f o "format" que va a definir si los números se presentarán como estandard (%g), exponencial o notacion cientifica(%e), o con punto decimal y 6 posiciones decimales(%f)
prueba seq -f %g con %e y f% y veras estos formatos mas claramente, pero la fuerza de -f no radica exactamente en estos 3 formatos, sino en los formatos adicionales que se pueden crear a traves de estos. Y es que -f tambien puede ser "archivo%02g.txt" o "logfile.%03g" asi
~\> seq -f "logfile.%03g" 5
logfile.001
logfile.002
logfile.003
logfile.004
logfile.005
con lo que podemos usar seq para crear archivos por ejemplo asi:
touch $(seq -f "logfile.%03g" 5)
o para borrarlos, o crear directorios, etc.
SECUENCIAS CON JOT
SECUENCIAS CON ECHO
echo {1..9}
1 2 3 4 5 6 7 8 9
echo {5..1}
5 4 3 2 1
en este sentido es echo un poco mas poderoso que seq y jot ya que estas secuencias pueden ser tambien alfabeticas, como
echo {a..z}
echo {A..Z}
y reversas:
echo {z..a} a asi...
pero estas secuencias estaran siempre en la misma linea (a no ser que se acabe la pantalla entonces salta a la siguiente linea), y si quisieramos que los numeros esten uno bajo el otro necesitaremos a xargs asi
echo {1..10} | xargs -n1
cosa que podria parecer molesta depender de un segundo comando para esta opcion, aunque si lo miramos asi
echo {1..9} | xargs -n3
echo {a..y} | xargs -n5
tenemos como resultado unas bonitas matrices
pero la salida de { .. } la podemos utilizar en Unix de muchas otras maneras mas alla de echo, ya que echo es solo un repetidor que saca cosas por la salida estandar stdout o por otra dirigida con direccionamientos > o pipes
asi podemos directamente crear el efecto de arriba en ~\> seq -f "logfile.%03g" 5
con:
touch logfile.00{1..5}
crear directorios:
md directorio_{a..z} ó sino tambien md {a..z}_directorio
con XARGS podemos
cambiar derechos de grupos de usuarios en todas las carpetas dentro del directorio listado:
o lo que seria aún mejor, cambiar los derechos de sólo algunos directorios que cumplan con alguna condición como los que comienzen con "a"
ls a* | xargs sudo chgrp wheel
o filtrarlo con find:
find d* -*k-z
miércoles, 5 de octubre de 2016
Instalando Webmin...
Cada vez que tengo que instalarme el Webmin me topo con algunos problemas extranos, que me derivan a la misma solucion: la instalacion alternativa a traves del depositorio.
Como esta solucion siempre funciona, aqui la copio para que la proxima vez no la tenga que buscar demasiado:
Using the Webmin APT repository
If you like to install and update Webmin via APT, edit the /etc/apt/sources.list file on your system and add the line :
deb http://download.webmin.com/download/repository sarge contrib
You should also fetch and install my GPG key with which the repository is signed, with the commands :
cd /root
wget http://www.webmin.com/jcameron-key.asc
apt-key add jcameron-key.ascYou will now be able to install with the commands :apt-get update
apt-get install webminAll dependencies should be resolved automatically.
Es la copia textual del manual online en
http://www.webmin.com/deb.html
Borrar winsxs en Windows 2008
En estos tiempos de Discos grandes rapidos y baratos pudiera parecer una tontería, pero siempre hay alguna situacion en la que se puede presentar la necesidad de ganar espacio en el Disco duro de nuestro servidor sin tener que instalar nuevos. Incluso yo diria que es mejor practica, limpiar que simplemente dejar crecer y crecer. Un buen sucio que nos ahorrara unos 15 GB de espacio en Disco y que realmente puede ser poco necesario es el directorio de WINSXS
La finalidad del directorio WINSXS es la de proveer los paquetes de instalacion de Windows en el caso de que deseemos instalar nuevos Roles o Features en nuestro Servidor. Si el servidor ya esta madurito, cumple sus funciones sin problemas y no queremos enconchinarlo, seguramente que estos archivos estan demas. Por otro lado el eliminarlos del Disco no va a significar que nunca mas podamos instalar nuevos roles, sino que podemos ubicar el WINSXS en una carpeta compartida de red donde todos los servidores puedan accederla para sus instalaciones. Si WINSXS tiene 15GB y tenemos 11 Servidores esta reduccion nos estará significando 150GB de espacio, lo que no es poco.
Para eliminar el WINSXS debemos realizar lo siguiente:
1.- Instalar la Feature "Desktop Experience" con "ink Support"
2.- Reiniciar el servidor
3.- Ahora tendremos en las herramientas del sistema, el "limpiador de Disco"
4.- Seleccionar el "Windows update Cleanup"




La finalidad del directorio WINSXS es la de proveer los paquetes de instalacion de Windows en el caso de que deseemos instalar nuevos Roles o Features en nuestro Servidor. Si el servidor ya esta madurito, cumple sus funciones sin problemas y no queremos enconchinarlo, seguramente que estos archivos estan demas. Por otro lado el eliminarlos del Disco no va a significar que nunca mas podamos instalar nuevos roles, sino que podemos ubicar el WINSXS en una carpeta compartida de red donde todos los servidores puedan accederla para sus instalaciones. Si WINSXS tiene 15GB y tenemos 11 Servidores esta reduccion nos estará significando 150GB de espacio, lo que no es poco.
Para eliminar el WINSXS debemos realizar lo siguiente:
1.- Instalar la Feature "Desktop Experience" con "ink Support"
2.- Reiniciar el servidor
3.- Ahora tendremos en las herramientas del sistema, el "limpiador de Disco"
4.- Seleccionar el "Windows update Cleanup"




este update es necesario, pero ya no hay que bajarlo extra sino que viene con los updates automaticos
Powershell Tipps y tops
las Funciones:
function [<scope:>]<name> [([type]$parameter1[,[type]$parameter2])]{el scope, normal es local, pero se puede poner "global" para que la funcion trabaje a nivel de sistematype, pude ser bool, string, etc. Por lo visto se puede obviar en algunos casos$parameter es el nombre de una variable que funcionara como parametro para la funcion, asi:funtion global:buscar [([string]$cosaabuscar)]{}para que el programa sea mas legible, tambien se pueden poner los parametros con la etiqueta "param" asi:param([type]$parameter1 [,[type]$parameter2])
Aqui un ejemplo de la especificidad que se puede alcanzar:#function [<scope:>]<name> [([type]$parameter1[,[type]$parameter2])]{ param([type]$parameter1 [,[type]$parameter2])
dynamicparam {<statement list>} begin {<statement list>}
process {<statement list>}
end {<statement list>}}si un parametro es obligatorio se puede usar el atributo de parametro "mandatory"
function Start-App{ Param(
[parameter(Mandatory=$true)]
[String]$AppNamePowershell tiene tambien otros atributos como por ejemplo:AllowNull
AllowEmptyString
ValidateCount
ValidateLength
ValidatePatternMATRICESUna funcion puede almacenar un Array de la siguiente manera:function myping {
$compname = $args[0]
$ip = $args[1]
ping $args[0,1]
}el array args, ejecutara el ping para ip o para computername, pero no para ambosVALORES LOGICOSen PS basta que una variable tenga un valor para ser verdadera, asi si hacemos$var="hola" if ($var){echo "es verdad"} el resultado sera ver en pantalla "es verdad"
los operadores son un poco extranos, es mejor al empezar hacerse una tabla:| -eq | equal |
| -ne | not equal |
| -lt | little |
| -le | little or equal |
| -gt | grande? |
| -ge | grande or equal |
se usan como un signo: $var -eq 10otros operadores muy útiles son tambien en lugar de decir $var = 10, cosa que al final de cuentas tambien es valida
viernes, 1 de abril de 2016
Ver las conversaciones pasadas del chat por Pidgin para Windows 7
Pidgin guarda sus conversacionen en la siguienter Ruta
C:\Users\<<NombreDeUsuario>>\AppData\Roaming\.purple\logs
Cada conversacion cerrada esta archivada como html por fechas asi
2016-04-01.085222+0200CET
C:\Users\<<NombreDeUsuario>>\AppData\Roaming\.purple\logs
Cada conversacion cerrada esta archivada como html por fechas asi
2016-04-01.085222+0200CET
Suscribirse a:
Comentarios (Atom)